統計学勉強会 第01回
03- Rでオッズ比を計算する
◆SPSSでsav形式ファイルをcsvで出力する
Rは様々なファイルを取り込み分析に利用できるが、csv形式で使用するのが標準的。SPSS形式の取り込みにメリットがない。
[ファイル]→[名前を付けて保存]→[次のタイプで保存]をcsvにする。
[エンコード]をローカルエンコードにする。RはShift-JISで動くため。 ←ココ重要
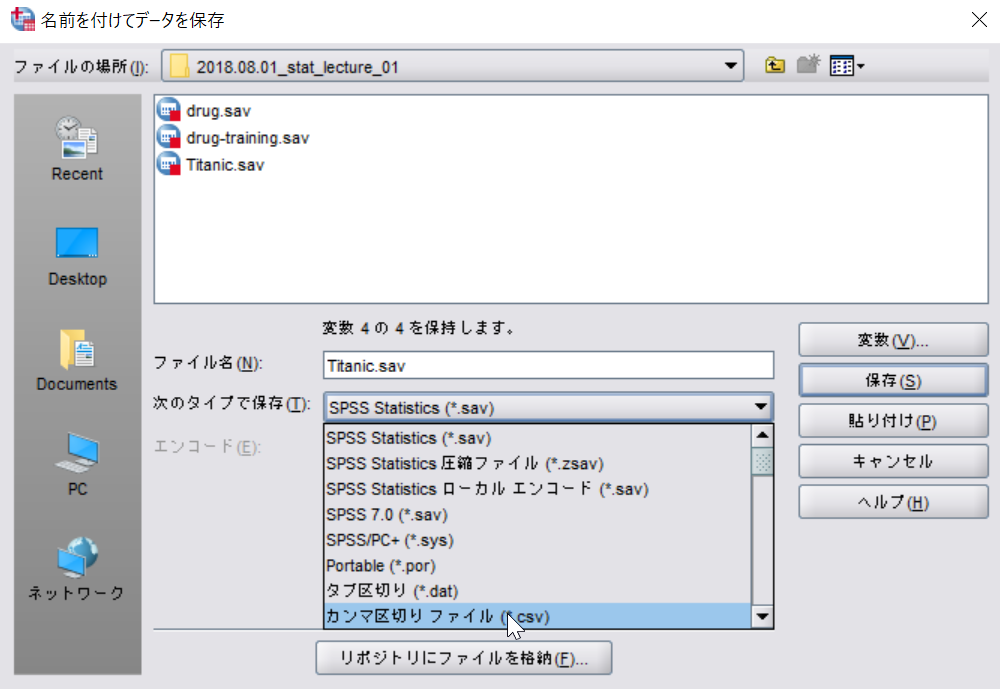
今回は"Taitanic.csv"という名前で保存する。
◆PSPPでsav形式ファイルをcsvで出力する
PSPPではGUI、マウス操作でcsv形式での保存(出力)はできない。
シンタックスを使う。
SAVE TRANSLATE
/OUTFILE="C:\R\Titanic.csv"
/REPLACE
/FIELDNAMES
/CELLS = VALUES
/TYPE = CSV.
OUTFILEで指定する保存先だけは間違えないようにする。ウィンドウで開いてコピペするのが確実。日本語を含まないパスにする。このシンタックスはSPSSでも使用できる。
Webサービスを使用する
PSPP File Conversion Service
https://pspp.benpfaff.org/
サービス提供者は誰かわからないが、コマンドラインを使わずにサービスを提供している。
参考: SPSS形式のデータをRで開く
http://cse.naro.affrc.go.jp/takezawa/r-tips/r/41.html
参考: Rを使って,SPSSデータをcsvファイルに変換する方法
練習用ファイル
練習用ファイル"Titanic.csv", enc="Shift-JIS"
◆Rでcsv形式のファイルを開く
Rを起動。
今回はRStudioではなく、Rを使う。
Rについての余談
Rは様々な面で便利なツールになる。
例えば、電卓の代わりに使用するなど。デスクトップからショートカットで呼び出せるように設定しておくと便利。
- Rを起動する。
RはGUI+マウス操作ではなく、コマンドラインによる操作で動かす(CUI)。SPSS以外の統計ソフトはCUIが大半。見慣れないため、難しそうに見えるが、初めのアレルギーさえ収まれば、簡単。
個人的に、通常のRを使う場合には、Cドライブ直下に"C:\R"というフォルダを作成してその中で作業している。ただ、多くの場合はR-Studioを使うので、Cドライブ直下のRフォルダはあまり使わない。
今回は"C:\R"を作成したしてコマンドを書く。この部分は適宜書き換える。
- Rの作業フォルダを決める
[ファイル]→[ディレクトリの変更]
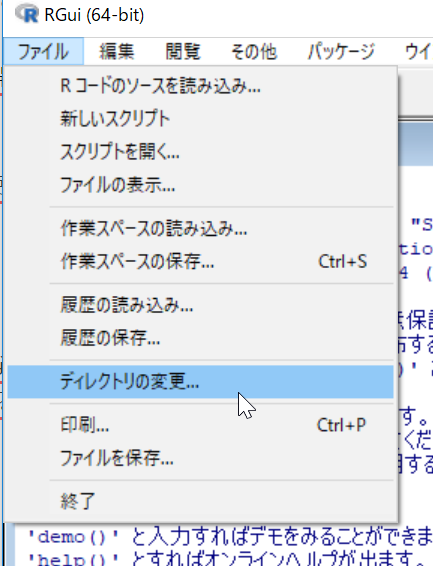
事前に作成した作業フォルダを選択する。
コマンドを使う
setwd("C:\\R")
理由はわからないが、\が一つ余分に必要。
- csv形式ファイルを読み込む
読み込み
d1<-read.csv("Titanic.csv")
d1というオブジェクトにタイタニックのファイルを格納するという意味。d1は任意。dはdataで、1番目という意味。d1をオブジェクトとして使う人は多い。他のものでもOK。符号は、"<-"でもよいし、"="でもよい。
データファイルのエンコードがUTF-8の場合は次のように書く
d1<-read.csv("Titanic.csv", encoding="UTF-8")
確認する
d1
ザーとデータが流れる。多すぎてわからない...
頭だけのデータを見ることが多い。
head(d1)
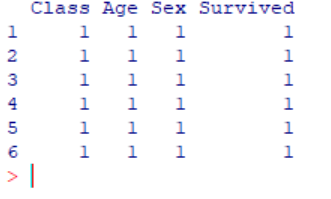
データの訂正はできない。ここでは、データを確認するだけ。特に、変数名の確認のためにこのコマンドは実行することが多い。
◆クロス集計表・カイ二乗検定・調整済み標準化残差
ct1 <- table(d1$Class, d1$Survived)
オブジェクトct1も任意。cross table1の略。オブジェクト名は任意。
結果の表示はオブジェクト名だけ打ち込めばいい。
> ct1
0 1
0 673 212
1 122 203
2 167 118
3 528 178
列が客室等級、行が生存。
> res01<- chisq.test(ct1) #カイ二乗検定
> res01 #カイ二乗検定の結果表示
Pearson's Chi-squared test
data: ct1
X-squared = 190.4, df = 3, p-value < 2.2e-16
> res01$stdres # 調整済み残差
0 1
0 6.868541 -6.868541
1 -12.593038 12.593038
2 -3.521022 3.521022
3 4.888701 -4.888701
SPSS/PSPPと同様の結果がでる。
オッズ比 (epitoolsパッケージ)
追加パッケージが必要。
◇ マウス操作でダウンロードする
[パッケージ]→[パッケージインストール]
ダウンロードするサイト(CRAN)を選ぶ。どこでもよい。ただCRANによって登録がないパッケージもあるので、パッケージがない場合には、べつのCRANを利用する。
次にパッケージが表示される。多くあり選ぶのが大変。表の中からepitoolsを探す。
◇ コマンドラインでダウンロードする
install.packages("epitools", dependencies = TRUE)
CRANのサイトを選ぶ必要はあるが、下記のコマンドの方が覚えやすい。
install.packages("epitools")
「 パッケージ ‘epitools’ は無事に展開され、MD5 サムもチェクされました」と出れば、インストール成功!
◇ パッケージを読みこむ
library(epitools) #epitoolsパッケージの読み込み
インストールは使用PCにつき1回、パッケージの読み込みは起動から閉じるまでの間につき1回。2回目からはしなくてよい。
◇ オッズ比を出す
> oddsratio(ct1)$measure
odds ratio with 95% C.I.
estimate lower upper
0 1.000000 NA NA
1 5.270800 4.0205924 6.938172
2 2.241656 1.6895793 2.971058
3 1.070276 0.8502303 1.346264
オッズ比が0.059、95%信頼区間が[0.008, 0.256]である。
以上をまとめると、以下のコマンドをテンプレにしておくと便利。
# 最初だけ行う作業
d1<-read.csv("Titanic.csv") # データの読み込み
install.packages("epitools") # パッケージのインストール(初回のみ)
library(epitools) #epitoolsパッケージの読み込み
ct1 <- table(d1$Class, d1$Survived) # どの変数か選ぶ
ct1 # クロス表の表示
res01<- chisq.test(ct1) #カイ二乗検定
res01 #カイ二乗検定の結果表示
res01$stdres # 調整済み残差
oddsratio(ct1)$measure # オッズ比の計算
Exercise 05
Rを使い、Titanicのデータで、以下のクロス集計表を作成する。
- 年齢×生存
- 性別×生存
- 客室等級×性別
- 客室等級×年齢
- 年齢×性別
一つのクロス表を作るのであれば、SPSS/PSPPで十分。オッズ比も手計算でできる。
しかし、分析する変数が多い場合には、Rの方が圧倒的に速くできる。オッズ比も少ない労力で計算ができる。
変数が多く、変数同士の関連を一つ一つ見ていくためには、Rをした方が速い。
参照:
Rでオッズ比と調整済み残差を出す-井出草平の研究ノート
余談・エンコードに気を付ける
SPSSやPSPPは基本的にエンコードにUTF-8を使用している。しかし、日本語のWindowsにRをインストールした場合には、Shift-JISに変更しておく。WindowsをUTF-8で作動させている場合には、エンコードは必要がない。。
Rのデータ読み込み時(read.csvの実行時)にUTF-8をしている方法もあり、基本的にはそちらの方法の方がよい。
参考: