統計学勉強会 第01回
01 - 解題・データの管理
今回の目標
分析の基礎はデータ管理。データ管理を適当にしていると、データが散乱し、分析結果を誤ることもしばしばある。また、研究ノートを簡便に作成し、5年後に見てもどのように分析したか、理解できるようにする。
やや説教臭いが、片付けと同じく、合理的な方法でその都度、整理整頓をしておくと、後々、「あれはどこいった」「あの時はどうしたんだ」と騒ぐこともない。
◇先んじて読んでおく記事
- PSPPのインストール・日本語化の方法
https://note.mu/xinzuzhai/n/n762cfb710a21
◆SPSSは便利だが問題も
- 価格が高い。
- 「よくある」分析しかできない。
SPSSでできないことの例
オッズ比の計算
信頼性・妥当性の計算
AICやBIC、ABIC、尤度比検定などのフィッテングに必要な指標・分析
難しい分析 など
価格が高い。ベースだけで13万程度。高度な分析を使用と思うと、追加でパッケージの購入が必要。例えば、回帰分析をするにはさらに7万程度が必要となる。パッケージ売りもしており、例えばSPSS メディカルパッケージは40万程度。
また、「よくある」分析しかできない。SPSSでできないことは割と多い。基礎統計量でも計算できない。
Rではだいたいのことができる。Rが使えると強みになる。もちろん、Rでできないこともあるので、その場合には他のソフトウェアを検討する。
-
マウス操作なので面倒
SPSSの一番のアピール点であるクリックで分析できる(GUI)は、分析に慣れてくると、欠点になる。計量分析では、何度も分析を繰り返すので、いちいちマウスでクリックするのは、面倒であり、分析にかかる時間も長くなる。
特に基礎統計量・記述統計をみる場合にはRで一気に行ってしまう方が速い。階層線形モデルなど、分析が少し複雑になると、GUI+マウス操作で行うSPSSの操作はややこしくなっているように思う。 -
SPSSは遅い・重い
SPSSはjavaを使ってプログラミングされているため鈍足である。PSPPはC+でプログラミングされており、処理速度がPSPPの方が格段に速い。モバイルPCでもサクサク分析ができる。Rはプログラミング言語のの中では処理が遅い部類だが、SPSSに比べると格段に速い。
フリーウェアを使って分析する場合には、データ管理をPSPPで行うのがよいと思う。
分析に関しては、
(1)PSPPでできる分析はPSPPでやって、できないものをRで行う、
(2)データ管理はPSPPで、分析はRを使用する、
のどちらかのパターンがよいと思う。
他の有料ソフトの紹介
- STATA...時系列・パネル分析に最適。マルチレベル分析(階層線形モデル)にも便利。その他分析も幅広く採用。ベイズによる検定も採用されたらしい(現バージョン未購入のため確認がとれない)。もし、有料ソフトを買うならSTATAがベスト。
- Mplus...構造方程式(SEM)を扱うソフトウェア。潜在変数を扱う場合はMplusがよい。対抗馬はLatant Gold。現実的には二択である。因子分析、潜在クラス分析などができる。Rでもある程度までは分析はできるが、近年の潜在変数の手技はパッケージが対応していないので、その場合にはMplusの購入を検討することになる(Latant Goldでもよい)。
◆データ管理に必要なのは「ラベル」概念
SPSS/PSPPでは「値」「変数名」「ラベル」「値ラベル」を設定する。
- 値...データの値。
- 変数名...字数制限があり日本語不可。
- ラベル...日本語で変数の説明を入れる。
- 変数ラベル...1「賛成」2「反対」などの値の説明をするラベル
SPSS

PSPP

日本語でのラベルが設定できるのはSPSS/PSPP、STATA15以降(STATA14までは英字のみ)から。日本語は少ない文字で表現ができるので英語より便利。
Rのデータフレームは、基本的にラベルの設定ができない。変数の少ないデータのにはよいが、変数が多いデータセットをRで管理するのは、あまりお勧めできない。
→ SPSS/PSPP、STATAでデータ管理を行うのがおすすめ。
◆「変数名」「ラベル」「変数ラベル」をつける
変数名=名前
ラベル=ラベル
値=変数ラベル
値ラベルの付け方
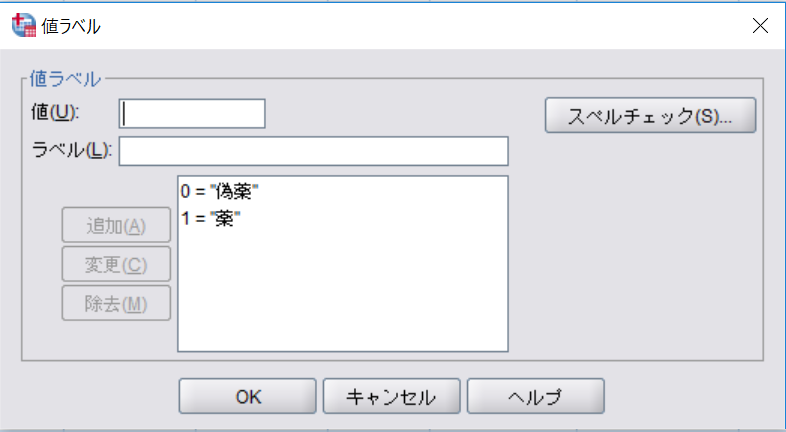
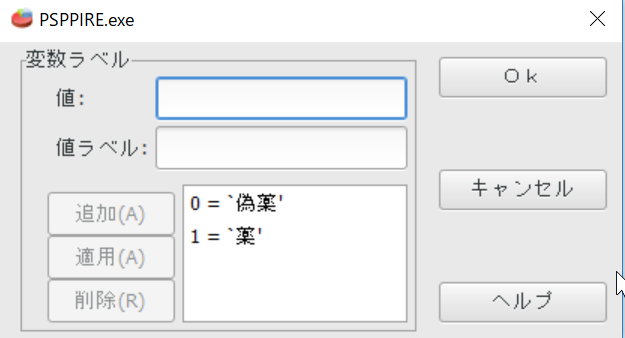
値ラベルを付けておくと、調査票をいちいち見る必要がない。調査票と突き合わせる時に、質問番号・選択肢を間違えミスが起こりやすい。値ラベルをつけるとはそれらのミスを防ぐことができる。
Exercise 01
SPSS形式ファイル(.sav)の練習用ファイル"drug-training.sav"を開き、上記のように「変数名」「ラベル」「値ラベル」をつけよう!
◇ エンコードに気を付ける
古い日本語版のSPSSはShift-JIS(ローカル・エンコード)で記録がされている場合がある。古いSPSSはShift-JISでも対応してくれるが、PSPPはユニコード(UTF-8)のみ。なるべくユニコードでの保存を心がける。
参照:
コード ページ文字エンコードでデータ ファイルを保存するには
https://www.ibm.com/support/knowledgecenter/ja/SSLVMB_24.0.0/spss/base/savedata_codepage_howto.html
◆分析の基本はデータセットからの切り出し
社会調査では変数が100を超えることも稀ではない。フル項目が入ったデータセットで分析をするのは避けた方がよい。
ここではSPSS/PSPPをデータ管理に使用しているので、SPSSでマザーに当たるデータセットを作成する。分析をする際には、このデータセットから必要なものだけを切り出し、別のデータセットで分析するのがよい。
マザーデータと分析に使うデータを分けるのは重要。一つのデータセットで様々な分析をすると、リコードした変数やフィルター変数など、どんどんと増えていき、収拾がつかなくなる。なんのために作った変数なのかも、そのうち忘れる。
整理整頓のために、データは切り出し使うクセをつけるのがおすすめ。必ず、データについての説明をテキストファイルなどで書くことも忘れずに。
◆SPSSで選んだ変数で分析データ作成
- メニューから[ファイル]-[名前を付けて保存]
- [変数]
- 必要な変数のみにチェックをいれて[続行]
- 新しい名前をつけて保存
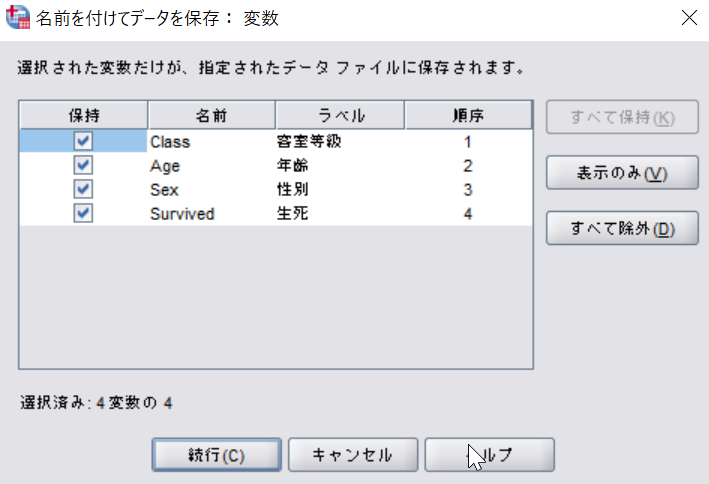
Exercise 02
練習用ファイル"Titanic.sav"をダウンロードして、ClassとSurvivedの変数だけ残して新しいファイル"Titanic02.sav"を作成しよう!(; ・`д・´)
◆PSPPで選んだ変数で分析データ作成
SPSSのように保存時に変数を選択して新しいデータを作ることができない。以下の2つの方法で新規ファイルを作成できる。
-
ファイルを複製し、不要な変数を削除する。
-
シンタックス・コマンドを使う。
最初は抵抗があるが、慣れれば無問題。
SAVE OUTFILE='C:\Dropbox\Titanic02.sav'
/KEEP= class Survived
/COMPRESSED.
1行目はファイル名。PSPPは日本語(2バイト文字)を認識しないので、英数字だけで構成される場所に保存する。ユーザー名が英数字であれば、デスクトップに保存できる。また、C:\Dropboxなどクラウドでもよいし、それができない場合には、C:\RなどC:直下のフォルダを作成してもよい。
2行目は保存する変数名(名前)。ラベルではない。必要のある変数を指定(KEEP)、不要な変数を指定する(DROP)。通常はKEEPかDROPのどちらかのコマンドのみを使う。応用編は以下リンク先。
参照:
DROP and KEEP subcommands (SAVE DATA COLLECTION command)
https://www.ibm.com/support/knowledgecenter/en/SSLVMB_23.0.0/spss/base/syn_save_dimensions_drop_keep.html
このシンタックスコマンドはSPSSでも実行可能。PSPPの機能でGUI+マウス操作で使えるのは一部機能で、できないものはシンタックスでできる可能性がある。